Loki¶
Loki¶

Grafana Loki 是一套可以组合成一个功能齐全的日志堆栈组件,与其他日志记录系统不同,Loki 是基于仅索引有关日志元数据的想法而构建的:标签 (就像 Prometheus 标签一样)。日志数据本身被压缩然后并存储在对象存储(例如 S3 或 GCS)的块中,甚至存储在本地文件系统上,轻量级的索引和高度压缩的块简化了操作,并显著降低了 Loki 的成本,Loki 更适合中小团队。由于 Loki 使用和 Prometheus 类似的标签概念,所以如果你熟悉 Prometheus 那么将很容易上手,也可以直接和 Grafana 集成,只需要添加 Loki 数据源就可以开始查询日志数据了。
Loki 还提供了一个专门用于日志查询的 LogQL 查询语句,类似于 PromQL,通过 LogQL 我们可以很容易查询到需要的日志,也可以很轻松获取监控指标。Loki 还能够将 LogQL 查询直接转换为 Prometheus 指标。此外 Loki 允许我们定义有关 LogQL 指标的报警,并可以将它们和 Alertmanager 进行对接。
Grafana Loki 主要由 3 部分组成:
loki: 日志记录引擎,负责存储日志和处理查询promtail: 代理,负责收集日志并将其发送给 lokigrafana: UI 界面
概述¶
Loki 是一组可以组成功能齐全的日志收集堆栈的组件,与其他日志收集系统不同,Loki 的构建思想是仅为日志建立索引标签,而使原始日志消息保持未索引状态。这意味着 Loki 的运营成本更低,并且效率更高。
多租户¶
Loki 支持多租户,以使租户之间的数据完全分离。当 Loki 在多租户模式下运行时,所有数据(包括内存和长期存储中的数据)都由租户 ID 分区,该租户 ID 是从请求中的 X-Scope-OrgID HTTP 头中提取的。 当 Loki 不在多租户模式下时,将忽略 Header 头,并将租户 ID 设置为 fake,这将显示在索引和存储的块中。
运行模式¶
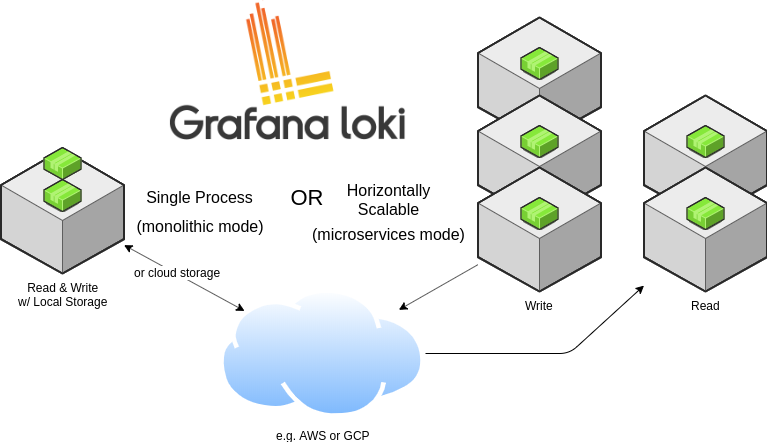
Loki 针对本地运行(或小规模运行)和水平扩展进行了优化,Loki 带有单一进程模式,可在一个进程中运行所有必需的微服务。单进程模式非常适合测试 Loki 或以小规模运行。为了实现水平可伸缩性,可以将 Loki 的服务拆分为单独的组件,从而使它们彼此独立地扩展。每个组件都产生一个用于内部请求的 gRPC 服务器和一个用于外部 API 请求的 HTTP 服务,所有组件都带有 HTTP 服务器,但是大多数只暴露就绪接口、运行状况和指标端点。
Loki 运行哪个组件取决于命令行中的 -target 标志或 Loki 的配置文件中的 target:<string> 配置。 当 target 的值为 all 时,Loki 将在单进程中运行其所有组件。,这称为单进程或单体模式。 使用 Helm 安装 Loki 时,单体模式是默认部署方式。
当 target 未设置为 all(即被设置为 querier、ingester、query-frontend 或 distributor),则可以说 Loki 在水平伸缩或微服务模式下运行。
Loki 的每个组件,例如 ingester 和 distributors 都使用 Loki 配置中定义的 gRPC 监听端口通过 gRPC 相互通信。当以单体模式运行组件时,仍然是这样的,尽管每个组件都以相同的进程运行,但它们仍将通过本地网络相互连接进行组件之间的通信。
单体模式非常适合于本地开发、小规模等场景,单体模式可以通过多个进程进行扩展,但有以下限制:
- 当运行带有多个副本的单体模式时,当前无法使用本地索引和本地存储,因为每个副本必须能够访问相同的存储后端,并且本地存储对于并发访问并不安全。
- 各个组件无法独立缩放,因此读取组件的数量不能超过写入组件的数量。
组件¶
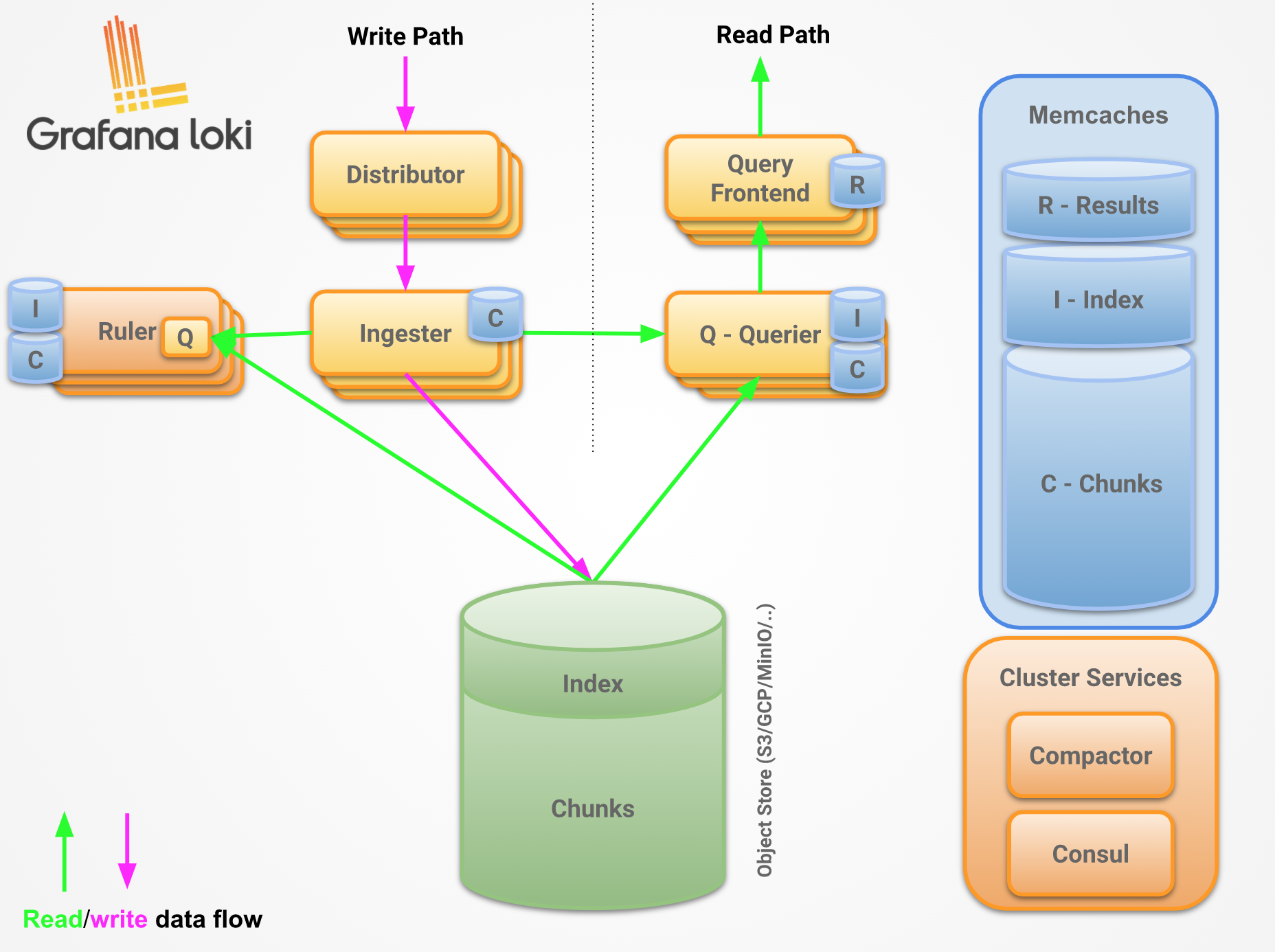
Distributor¶
distributor 服务负责处理客户端写入的日志,它本质上是日志数据写入路径中的第一站 ,一旦 distributor 收到日志数据,会将其拆分为多个批次,然后并行发送给多个 ingester。distributor 通过 gRPC 与 ingester 通信,它们都是无状态的,所以可以根据需要扩大或缩小规模。
Hashing
distributor 将一致性 Hash 和可配置的复制因子结合使用,以确定 ingester 服务的哪些实例应该接收指定的数据流。
流是一组与租户和唯一标签集 关联的日志,使用租户 ID 和标签集对流进行 hash 处理,然后使用哈希查询要发送流的 ingester。
存储在 Consul/Etcd 中的哈希环被用来实现一致性哈希,所有的 ingester 都会使用自己拥有的一组 Token 注册到哈希环中,每个 Token 是一个随机的无符号 32 位数字,与一组 Token 一起,ingester 将其状态注册到哈希环中,状态 JOINING 和 ACTIVE 都可以接收写请求,而 ACTIVE 和 LEAVING 的 ingester 可以接收读请求。在进行哈希查询时,distributor 只使用处于请求的适当状态的 ingester 的 Token。
为了进行哈希查找,distributor 找到最小合适的 Token,其值大于日志流的哈希值,当复制因子大于 1 时,属于不同 ingester 的下一个后续 Token(在环中顺时针方向)也将被包括在结果中。
这种哈希配置的效果是,一个 ingester 拥有的每个 Token 都负责一个范围的哈希值,如果有三个值为 0、25 和 50 的 Token,那么 3 的哈希值将被给予拥有 25 这个 Token 的 ingester,拥有 25 这个 Token 的 ingester 负责1-25的哈希值范围。
Ingester¶
ingester 负责接收 distributor 发送过来的日志数据,存储日志的索引数据以及内容数据。此外 ingester 会验证摄取的日志行是否按照时间戳递增的顺序接收的(即每条日志的时间戳都比前面的日志晚一些),当 ingester 收到不符合这个顺序的日志时,该日志行会被拒绝并返回一个错误。
- 如果传入的行与之前收到的行完全匹配(与之前的时间戳和日志文本都匹配),传入的行将被视为完全重复并被忽略。
- 如果传入的行与前一行的时间戳相同,但内容不同,则接受该日志行,表示同一时间戳有两个不同的日志行是可能的。
来自每个唯一标签集的日志在内存中被建立成 chunks(块),然后可以根据配置的时间间隔刷新到支持的后端存储。在下列情况下,块被压缩并标记为只读:
- 当前块容量已满(该值可配置)
- 过了太长时间没有更新当前块的内容
- 刷新了
每当一个数据块被压缩并标记为只读时,一个可写的数据块就会取代它。如果一个 ingester 进程崩溃或突然退出,所有尚未刷新的数据都会丢失,Loki 通常配置为多个副本来降低 这种风险。
当向持久存储刷新时,该块将根据其租户、标签和内容进行哈希处理,这意味着具有相同数据副本的多个 ingester 实例不会将相同的数据两次写入备份存储中,但如果对其中一个副本的写入失败,则会在备份存储中创建多个不同的块对象。
WAL
上面我们提到了 ingester 将数据临时存储在内存中,如果发生了崩溃,可能会导致数据丢失,而 WAL 就可以帮助我们来提高这方面的可靠性。
在计算机领域,WAL(Write-ahead logging,预写式日志)是数据库系统提供原子性和持久化的一系列技术。
在使用 WAL 的系统中,所有的修改都先被写入到日志中,然后再被应用到系统状态中。通常包含 redo 和 undo 两部分信息。为什么需要使用 WAL,然后包含 redo 和 undo 信息呢?举个例子,如果一个系统直接将变更应用到系统状态中,那么在机器断电重启之后系统需要知道操作是成功了,还是只有部分成功或者是失败了(为了恢复状态)。如果使用了 WAL,那么在重启之后系统可以通过比较日志和系统状态来决定是继续完成操作还是撤销操作。
redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生断电之类的情况时系统可以在重启后继续操作。undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。
Loki 中的 WAL 记录了传入的数据,并将其存储在本地文件系统中,以保证在进程崩溃的情况下持久保存已确认的数据。重新启动后,Loki 将重放 日志中的所有数据,然后将自身注册,准备进行后续写操作。这使得 Loki 能够保持在内存中缓冲数据的性能和成本优势,以及持久性优势(一旦写被确认,它就不会丢失数据)。
Querier¶
Querier 接收日志数据查询、聚合统计请求,使用 LogQL 查询语言处理查询,从 ingester 和长期存储中获取日志。
查询器查询所有 ingester 的内存数据,然后再到后端存储运行相同的查询。由于复制因子,查询器有可能会收到重复的数据。为了解决这个问题,查询器在内部对具有相同纳秒时间戳、标签集和日志信息的数据进行重复数据删除。
Query Frontend¶
Query Frontend 查询前端是一个可选的服务,可以用来加速读取路径。当查询前端就位时,将传入的查询请求定向到查询前端,而不是 querier, 为了执行实际的查询,群集中仍需要 querier 服务。
查询前端在内部执行一些查询调整,并在内部队列中保存查询。querier 作为 workers 从队列中提取作业,执行它们,并将它们返回到查询前端进行汇总。querier 需要配置查询前端地址,以便允许它们连接到查询前端。
查询前端是无状态的,然而,由于内部队列的工作方式,建议运行几个查询前台的副本,以获得公平调度的好处,在大多数情况下,两个副本应该足够了。
队列
查询前端的排队机制用于:
- 确保可能导致
querier出现内存不足(OOM)错误的查询在失败时被重试。这样管理员就可以为查询提供稍低的内存,或者并行运行更多的小型查询,这有助于降低总成本。 - 通过使用先进先出队列(FIFO)将多个大型请求分配到所有
querier上,以防止在单个querier中进行多个大型请求。 - 通过在租户之间公平调度查询。
分割
查询前端将较大的查询分割成多个较小的查询,在下游 querier 上并行执行这些查询,并将结果再次拼接起来。这可以防止大型查询在单个查询器中造成内存不足的问题,并有助于更快地执行这些查询。
缓存
查询前端支持缓存查询结果,并在后续查询中重复使用。如果缓存的结果不完整,查询前端会计算所需的子查询,并在下游 querier 上并行执行这些子查询。查询前端可以选择将查询与其 step 参数对齐,以提高查询结果的可缓存性。
读取路径¶
日志读取路径的流程如下所示:
- 查询器收到一个对数据的 HTTP 请求。
- 查询器将查询传递给所有
ingester。 ingester收到读取请求,并返回与查询相匹配的数据。- 如果没有
ingester返回数据,查询器会从后端存储加载数据,并对其运行查询。 - 查询器对所有收到的数据进行迭代和重复计算,通过 HTTP 连接返回最后一组数据。
写入路径¶

整体的日志写入路径如下所示:
distributor收到一个 HTTP 请求,以存储流的数据。- 每个流都使用哈希环进行哈希操作。
distributor将每个流发送到合适的ingester和他们的副本(基于配置的复制因子)。- 每个
ingester将为日志流数据创建一个块或附加到一个现有的块上。每个租户和每个标签集的块是唯一的。
安装¶
首先添加 Loki 的 Chart 仓库:
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update
获取 loki-stack 的 Chart 包并解压:
$ helm pull grafana/loki-stack --untar --version 2.6.4
loki-stack 这个 Chart 包里面包含所有的 Loki 相关工具依赖,在安装的时候可以根据需要开启或关闭,比如我们想要安装 Grafana,则可以在安装的时候简单设置 --set grafana.enabled=true 即可。默认情况下 loki、promtail 是自动开启的,也可以根据我们的需要选择使用 filebeat 或者 logstash,同样在 Chart 包根目录下面创建用于安装的 Values 文件:
# values-prod.yaml
loki:
enabled: true
replicas: 1
rbac:
pspEnabled: false
persistence:
enabled: true
storageClassName: local-path
promtail:
enabled: true
rbac:
pspEnabled: false
grafana:
enabled: true
service:
type: NodePort
rbac:
pspEnabled: false
persistence:
enabled: true
storageClassName: local-path
accessModes:
- ReadWriteOnce
size: 1Gi
然后直接使用上面的 Values 文件进行安装即可:
$ helm upgrade --install loki -n logging -f values-prod.yaml .
Release "loki" does not exist. Installing it now.
NAME: loki
LAST DEPLOYED: Tue Jun 14 14:45:50 2022
NAMESPACE: logging
STATUS: deployed
REVISION: 1
NOTES:
The Loki stack has been deployed to your cluster. Loki can now be added as a datasource in Grafana.
See http://docs.grafana.org/features/datasources/loki/ for more detail.
安装完成后可以查看 Pod 的状态:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 5m19s
loki-grafana-5f9df99f6d-8rwbz 2/2 Running 0 5m19s
loki-promtail-ptxxl 1/1 Running 0 5m19s
loki-promtail-xc55z 1/1 Running 0 5m19s
loki-promtail-zg9tv 1/1 Running 0 5m19s
这里我们为 Grafana 设置的 NodePort 类型的 Service:
$ kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 10.104.186.9 <none> 3100/TCP 5m34s
loki-grafana NodePort 10.110.58.196 <none> 80:31634/TCP 5m34s
loki-headless ClusterIP None <none> 3100/TCP 5m34s
可以通过 NodePort 端口 31634 访问 Grafana,使用下面的命令获取 Grafana 的登录密码:
$ kubectl get secret --namespace logging loki-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
使用用户名 admin 和上面的获取的密码即可登录 Grafana,由于 Helm Chart 已经为 Grafana 配置好了 Loki 的数据源,所以我们可以直接获取到日志数据了。点击左侧 Explore 菜单,然后就可以筛选 Loki 的日志数据了:
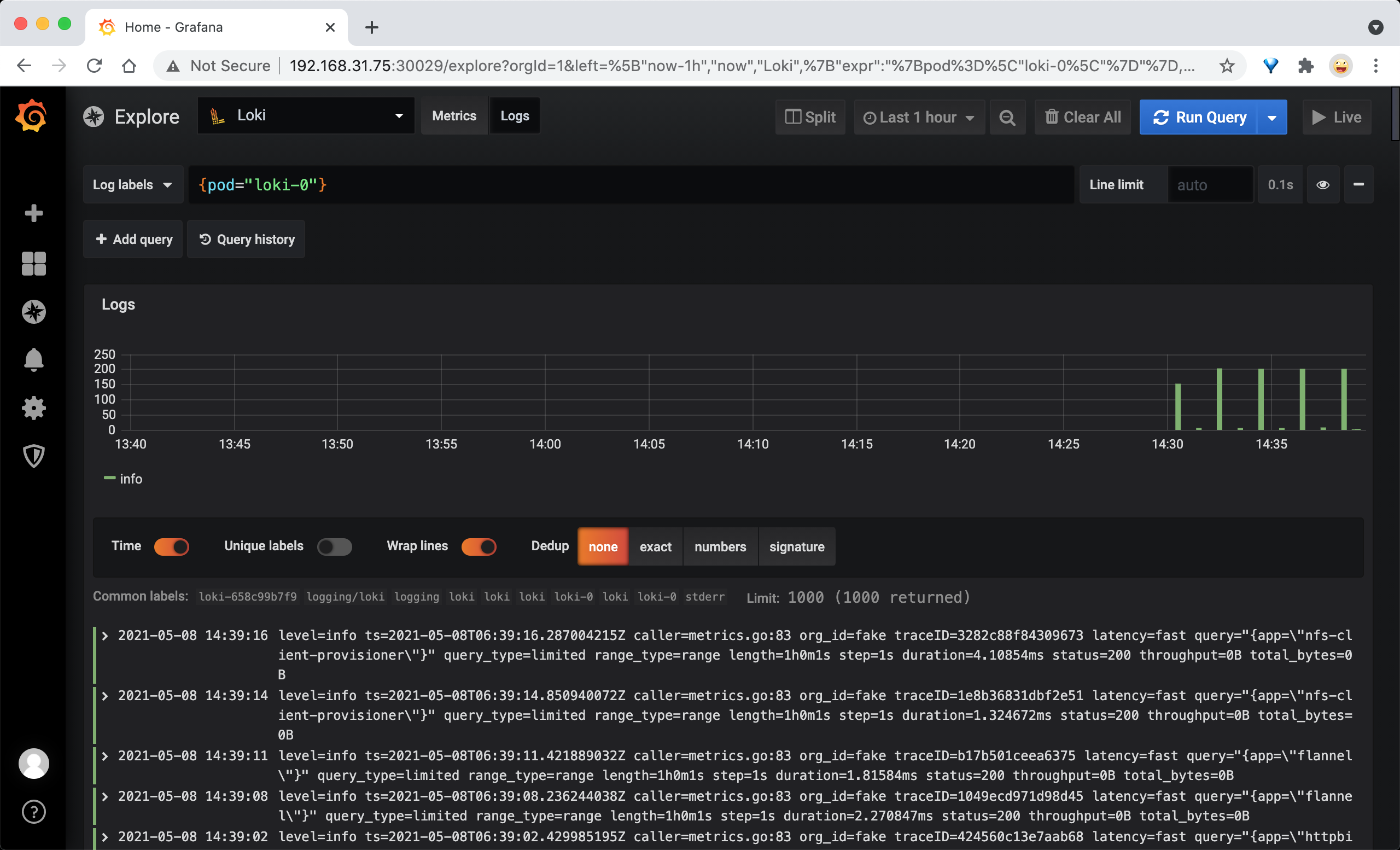
我们使用 Helm 安装的 Promtail 默认已经帮我们做好了配置,已经针对 Kubernetes 做了优化,我们可以查看其配置:
$ kubectl get secret loki-promtail -n logging -o json | jq -r '.data."promtail.yaml"' | base64 --decode
server:
log_level: info
http_listen_port: 3101
client:
url: http://loki:3100/loki/api/v1/push
positions:
filename: /run/promtail/positions.yaml
scrape_configs:
# See also https://github.com/grafana/loki/blob/master/production/ksonnet/promtail/scrape_config.libsonnet for reference
- job_name: kubernetes-pods
pipeline_stages:
- cri: {}
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_controller_name
regex: ([0-9a-z-.]+?)(-[0-9a-f]{8,10})?
action: replace
target_label: __tmp_controller_name
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_name
- __meta_kubernetes_pod_label_app
- __tmp_controller_name
- __meta_kubernetes_pod_name
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: app
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_component
- __meta_kubernetes_pod_label_component
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: component
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node_name
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: $1
separator: /
source_labels:
- namespace
- app
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- action: replace
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
- action: replace
regex: true/(.*)
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_annotationpresent_kubernetes_io_config_hash
- __meta_kubernetes_pod_annotation_kubernetes_io_config_hash
- __meta_kubernetes_pod_container_name
target_label: __path__
收集 Traefik 日志¶
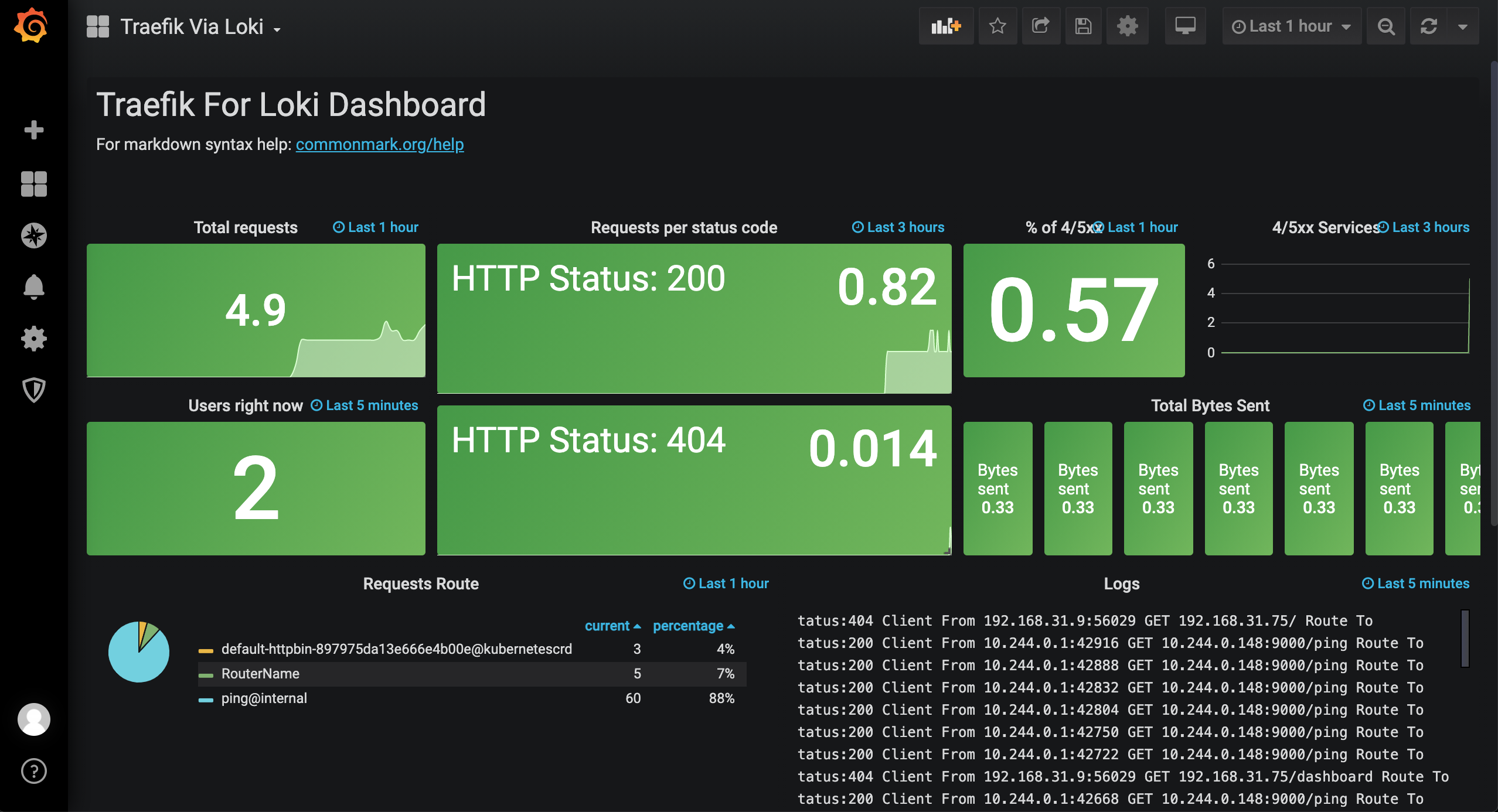
这里我们以收集 Traefik 为例,为 Traefik 定制一个可视化的 Dashboard,默认情况下访问日志没有输出到 stdout,我们可以通过在命令行参数中设置 --accesslog=true 来开启,此外我们还可以设置访问日志格式为 json,这样更方便在 Loki 中查询使用:
containers:
- args:
- --accesslog=true
- --accesslog.format=json
......
默认 traefik 的日志输出为 stdout,如果你的采集端是通过读取文件的话,则需要用 filePath 参数将 traefik 的日志重定向到文件目录。
修改完成后正常在 Grafana 中就可以看到 Traefik 的访问日志了:
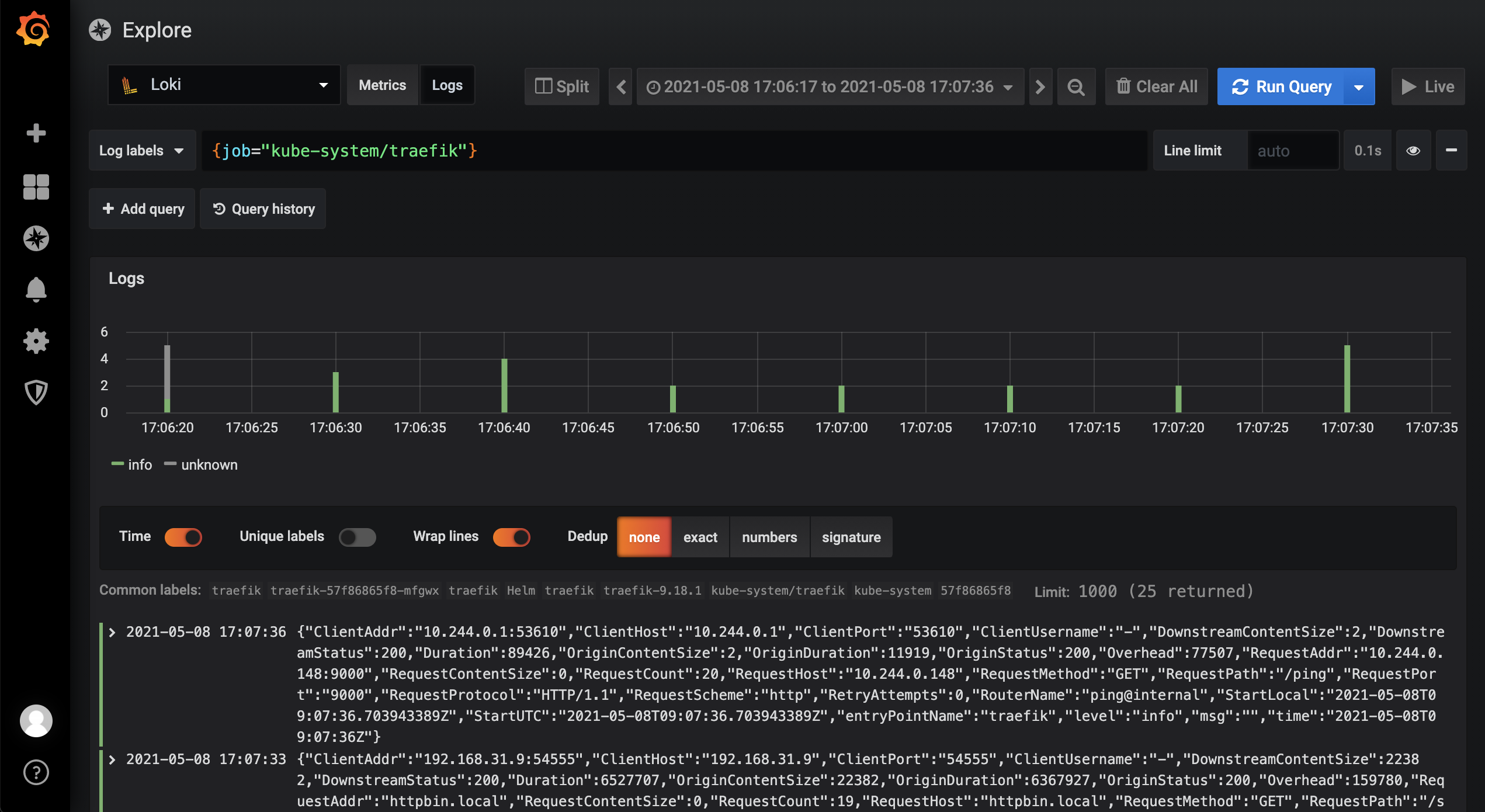
然后我们还可以导入 Dashboard 来展示 Traefik 的信息:https://grafana.com/grafana/dashboards/13713,在 Grafana 中导入 13713 号 Dashboard:
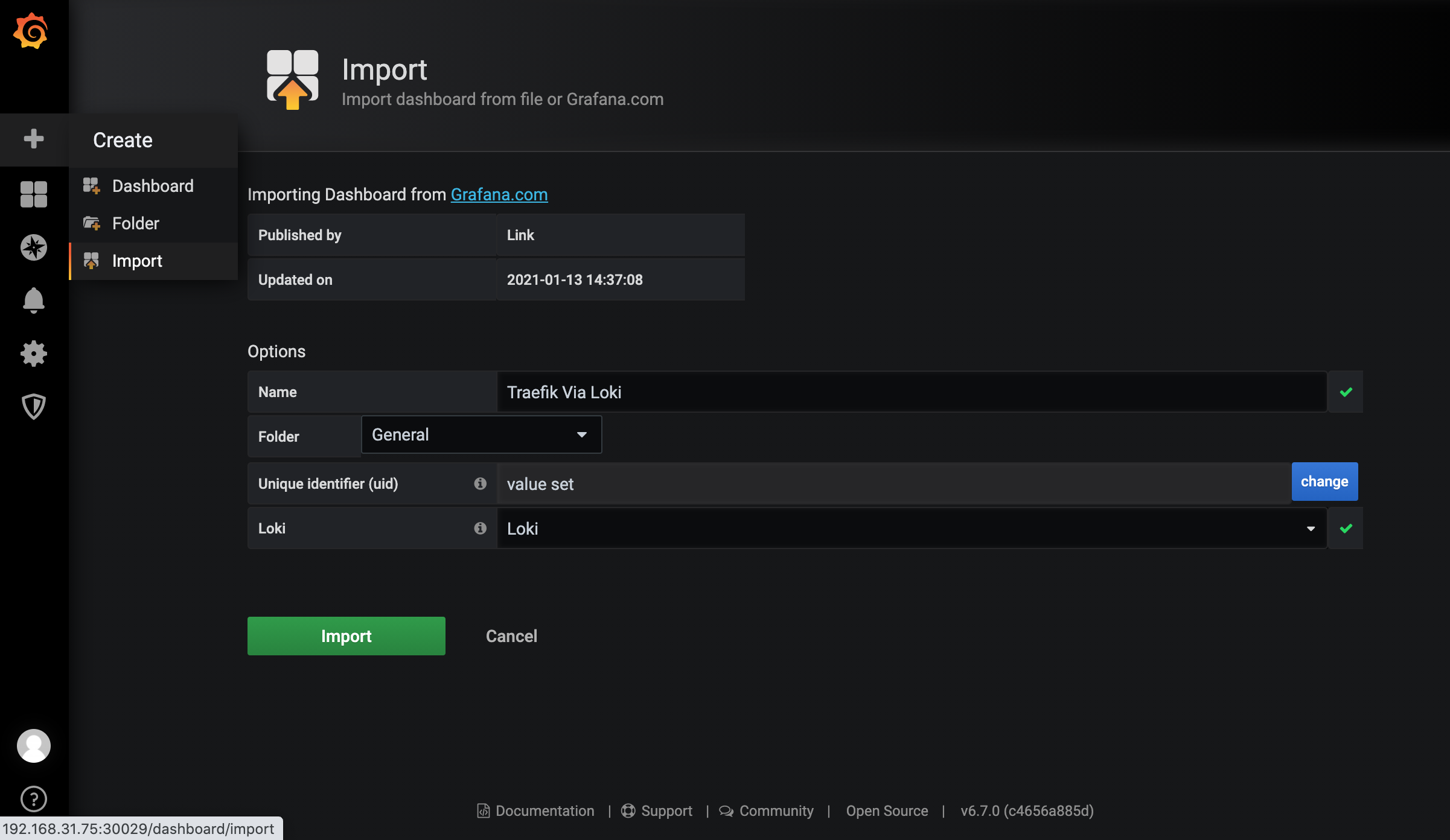
不过要注意我们需要更改 Dashboard 里面图表的查询语句,将 job 的值更改为你实际的标签,比如我这里采集 Traefik 日志的最终标签为 job="kube-system/traefik":
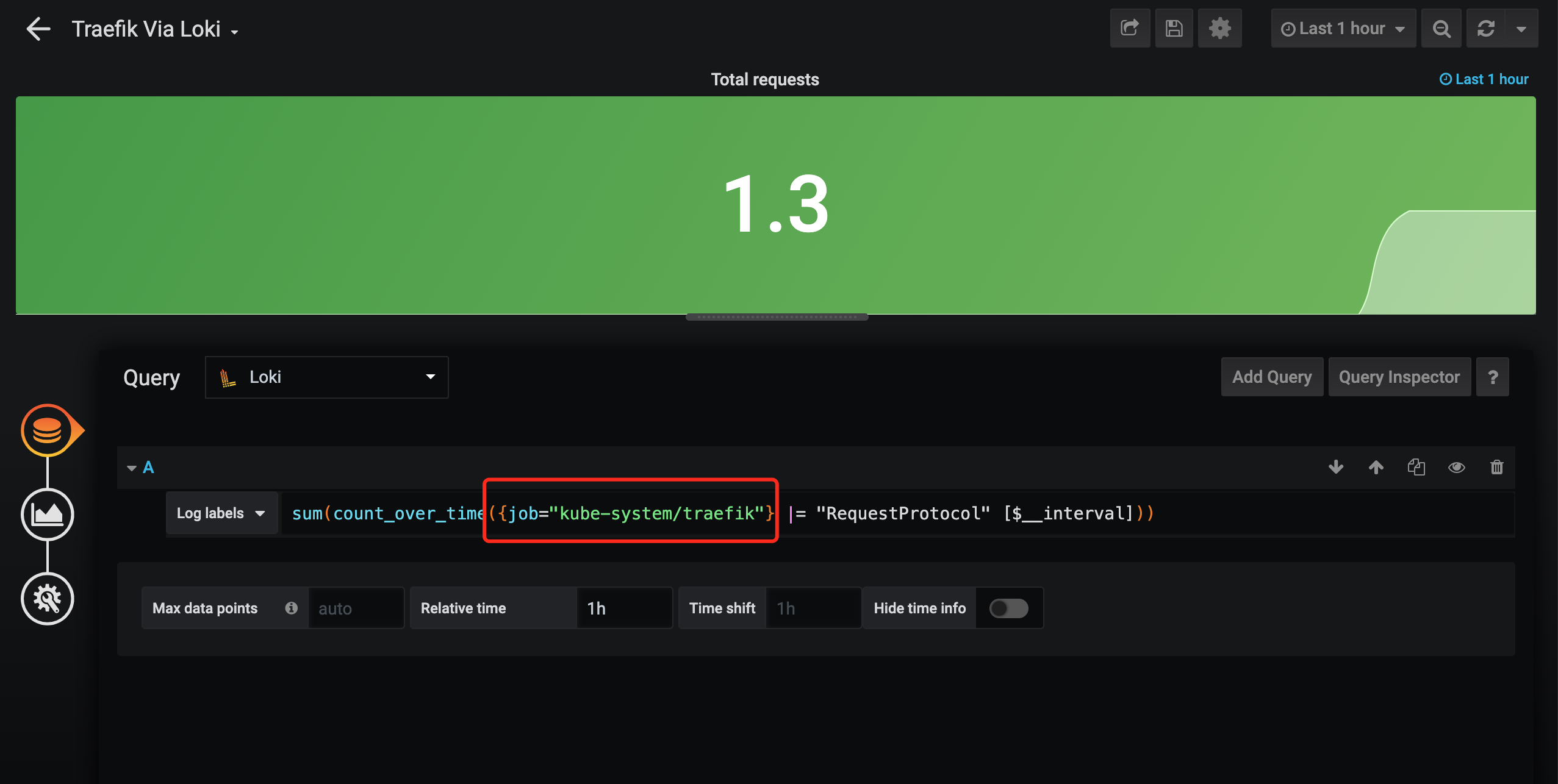
此外该 Dashboard 上还出现了 Panel plugin not found: grafana-piechart-panel 这样的提示,这是因为该面板依赖 grafana-piechart-panel 这个插件,我们进入 Grafana 容器内安装重建 Pod 即可:
$ kubectl exec -it loki-grafana-864fc6999c-z9587 -n logging -- /bin/bash
bash-5.0$ grafana-cli plugins install grafana-piechart-panel
installing grafana-piechart-panel @ 1.6.1
from: https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.6.1/download
into: /var/lib/grafana/plugins
✔ Installed grafana-piechart-panel successfully
Restart grafana after installing plugins . <service grafana-server restart>
由于上面我们安装的时候为 Grafana 持久化了数据,所以删掉 Pod 重建即可:
kubectl delete pod loki-grafana-864fc6999c-z9587 -n logging
pod "loki-grafana-864fc6999c-z9587" deleted
最后调整过后的 Traefik Dashboard 大盘效果如下所示: