ceph 高级参数
调整CRUSH结构¶
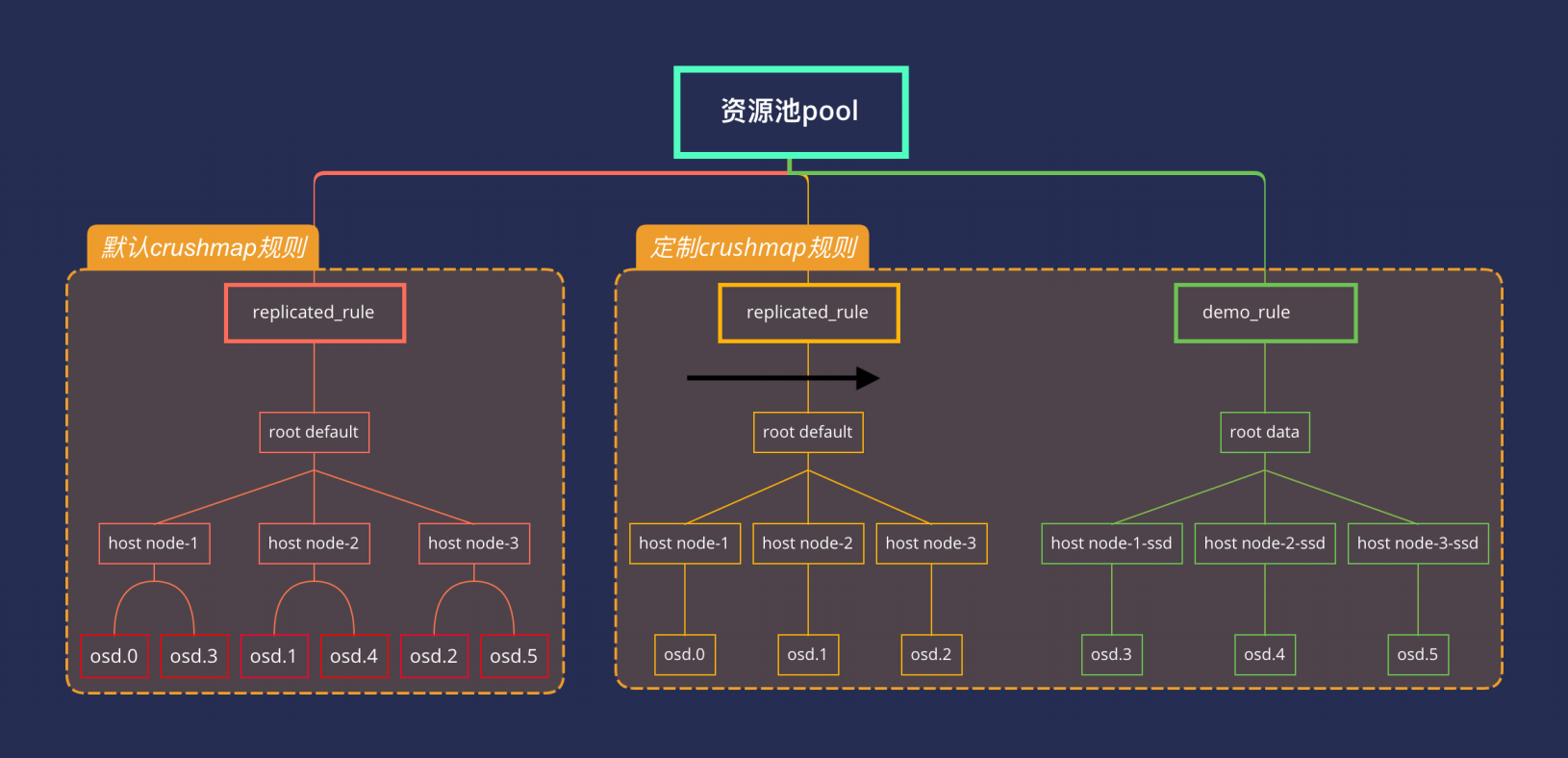
crushmap是Ceph决定数据分布的方式,一把采用默认的crushmap即可,有些场景需要做调整,如:
- 数据分布: 如SSD+HDD融合环境,需要将SSD资源池和HDD资源池分开,给两种不同的业务混合使用
- 权重分配: OSD默认会根据容量分配对应的weight,但数据不是绝对的平均,容量不平均的时候可以调整
- OSD亲和力: 调整OSD数据主写的亲和力机制
如某个OSD利用率过高,达到85%的时候会提示nearfull,这个时候需要扩容OSD到集群中,如果其他的OSD利用率不高,则可以根据需要调整OSD的权重,触发数据的重新分布,如下:
ceph osd crush reweight osd.3 0.8
定制OSD网络¶
Ceph 提供了两个不同的网络,用于不同的功能:
- public network 业务网络,用于连接Ceph集群建立数据通道
- cluster network 数据网络,用于Ceph内部的心跳,数据同步
默认这两个网络加成在一起,如果有两张不同的网卡,可以将其进行分开,首先需要将网络设置为hostNetwork,hostNetwork 意味着容器网络和宿主机网络位于同一个网络类型,这个调整只能在rook初始化集群的时候做调整,配置位于cluster.yaml文件
network:
provider: host
调整故障域¶
Ceph 支持设置资源池的故障域,何为故障域?故障域是指当出现异常时能容忍的范围,Ceph支持多种不同类型的故障域,常见的故障域有:
- datacenter : 数据中心级别,如三个副本,分别落在三个不同的数据中心
- rack : 机架级别,如三个副本,分别落在三个不同的数据机柜
- host : 宿主机级别,如三个副本,分别落在三个不同的宿主机,默认规则
- osd : 磁盘级别,如三个副本,分别落在三个不同的磁盘上
创建pool的时候可以定义pool所使用的故障域,如下创建一个pool所使用的故障域为osd
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: happylau-pool
namespace: rook-ceph
spec:
failureDomain: osd
replicated:
size: 3
requireSafeReplicaSize: true
ceph osd pool get happylau-pool crush_rule
ceph osd crush rule dump happylau-pool
常见故障排查¶
Rook将Ceph相关的组件运行在kubernetes之上,因此维护Ceph的时候需要同时维护kubernetes集群和Ceph集群,确保两个集群状态正常,通常Ceph依赖于kubernetes,然而kubernetes状态正常并不完全等同于Ceph正常,Ceph包含有内置的状态维护方法
1、对于kubernetes而言,需要确保相关的pods状态处于正常状态
$ kubectl get pods -n rook-ceph
$ kubectl logs pod-xxx -n rook-ceph -c pod-xxx
ceph -s 和详细的 ceph health detail
$ ceph -s
cluster:
id: 860fd586-3f2e-4bd7-8497-4f900de9cd32
health: HEALTH_WARN
11 pool(s) have no replicas configured
OSD count 1 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: b(active, since 2d), standbys: a
mds: 1/1 daemons up
osd: 1 osds: 1 up (since 2d), 1 in (since 11w)
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 11 pools, 168 pgs
objects: 95.32k objects, 22 GiB
usage: 23 GiB used, 931 GiB / 954 GiB avail
pgs: 168 active+clean
io:
client: 6.0 KiB/s rd, 22 KiB/s wr, 4 op/s rd, 7 op/s wr
$ ceph health detail
HEALTH_WARN 11 pool(s) have no replicas configured; OSD count 1 < osd_pool_default_size 3
[WRN] POOL_NO_REDUNDANCY: 11 pool(s) have no replicas configured
pool 'replicapool' has no replicas configured
pool 'myfs-metadata' has no replicas configured
pool 'myfs-replicated' has no replicas configured
pool 'my-store.rgw.otp' has no replicas configured
pool 'my-store.rgw.log' has no replicas configured
pool 'my-store.rgw.meta' has no replicas configured
pool 'my-store.rgw.control' has no replicas configured
pool 'my-store.rgw.buckets.non-ec' has no replicas configured
pool 'my-store.rgw.buckets.index' has no replicas configured
pool '.rgw.root' has no replicas configured
pool 'my-store.rgw.buckets.data' has no replicas configured
[WRN] TOO_FEW_OSDS: OSD count 1 < osd_pool_default_size 3
Ceph 集群健康状况警告表示你的集群中的存储池没有配置副本,且 OSD(对象存储设备)的数量少于默认的 osd_pool_default_size(默认值为3)。
这可能会导致数据丢失的风险,因为没有副本可以在一个 OSD 失败时提供备份。
初次之外,还提供了很多OSD得追昂体啊查看相关的工具
$ ceph osd tree # 查看osd的目录树结构
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.93149 root default
-3 0.93149 host m1-pre
0 ssd 0.93149 osd.0 up 1.00000 1.00000
$ ceph osd df # 查看osd的磁盘利用率
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 ssd 0.93149 1.00000 954 GiB 23 GiB 22 GiB 168 MiB 763 MiB 931 GiB 2.42 1.00 168 up
TOTAL 954 GiB 23 GiB 22 GiB 168 MiB 763 MiB 931 GiB 2.42
MIN/MAX VAR: 1.00/1.00 STDDEV: 0
$ ceph osd status # 查看osd集群状态
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 m1.pre 23.1G 930G 6 41.8k 5 2457 exists,up
$ ceph osd utilization # 查看osd的利用率
avg 168
stddev 0 (expected baseline 0)
min osd.0 with 168 pgs (1 * mean)
max osd.0 with 168 pgs (1 * mean)